Webブラウザのデフォルトエンコード
文字化けはページ提供者の責任
Webブラウザで閲覧しているページが文字化けすることがある。 文字化けは、Webコンテンツを提供している側の責任であって、閲覧している側の不手際ではない。 HTML構文指定とHTMLヘッダの文字コードにあるように、Webコンテンツとして書かれているHTMLファイルの文字コード(文字符号化)を<head>〜</head>内で次のように宣言しなければならない。
<meta charset="文字符号化法" />
文字符号化で説明しているように、 文字符号化法として代表的なものには、日本語関連では「Uft-8」(Unicode)、「Shift_JIS」「EUC-JP」「ISO-2022-JP」などがある。 HTMLファイルをどの文字符号化によって書く(保存する)かはコンテンツ提供者が決めることになる。 たとえば、Shift_JISの文字集合にはタイ文字(こんにちは สวัสดี)、アラビア文字(こんにちは اَلسَّلامُعَلَىْكُمْ)、ハングル文字(こんにちは안녕하십니까)などは含まれないので、Shift_JISファイルには日本語と混在して書くことができない(そのために、画像として貼りつけたりする必要がある)。
現在では多言語を同じページ内に表記する必要性が高まってるため、表記可能な文字集合がうんと大きなUTF-8によってテキストを書く(保存する)ように推奨する(このページもUTF-8で書かれている)。つまり、HTMLファイルを文字符号化UTF-8で保存し、<head>〜</head>内で次のように文字符号化指定するのである。
<meta charset="UTF-8" />テキストを書く場合、どの文字符号化で書いている(保存している)のかを常に意識することがたいへん重要になる。 必要に応じて文字符号変換し、保存した文字符号化に合致させた文字コード宣言を行わない限り、閲覧者に適切なコンテンツ提供ができないのである。 繰り返すが、文字化けは情報提供者の責任で回避しなければならない(閲覧者には何も届かないということだ)。
Webブラウザのデフォルトエンコーディング
Webページの文字化けは(文字コード宣言がなされていないのだが)、Webブラウザは事前に設定してある既定の文字符号化法で表示しようとするために生ずる。 既定の文字符号化設定をデフォルトエンコードという。 文字化けはたいへん忌々しいのだが、どうしてもその内容を知る必要のあるWebページでは、Webブラウザの符号化方法を一時的にでも変更して読まねばならない。
ブラウザのデフォルトエンコードを知る
Webブラウザごとにデフォルトエンコードが設定されている。 これを知ることはWeb閲覧における基本的知識である。
- Ver.35以降:[設定]/[詳細設定]/[ウェブコンテンツ]/[フォントをカスタマイズ]にある「エンコード」から選択(その様子表示する)。 あるいは 、フォント、言語、エンコードを変更する参照。
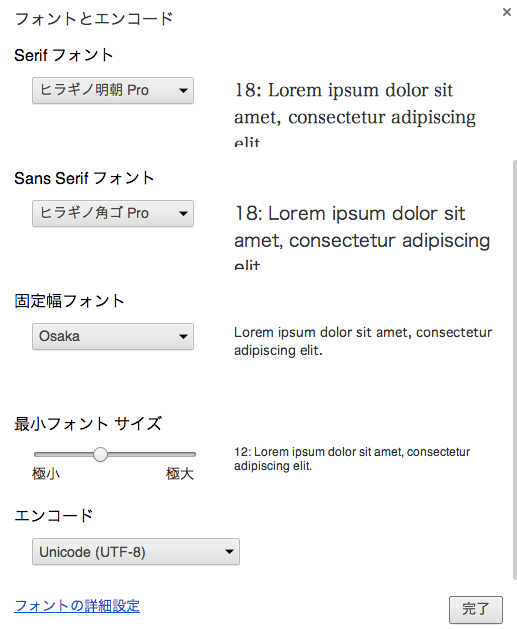
- [環境設定]/[詳細]にある「デフォルトのエンコーディング」から選択(その様子を表示する)
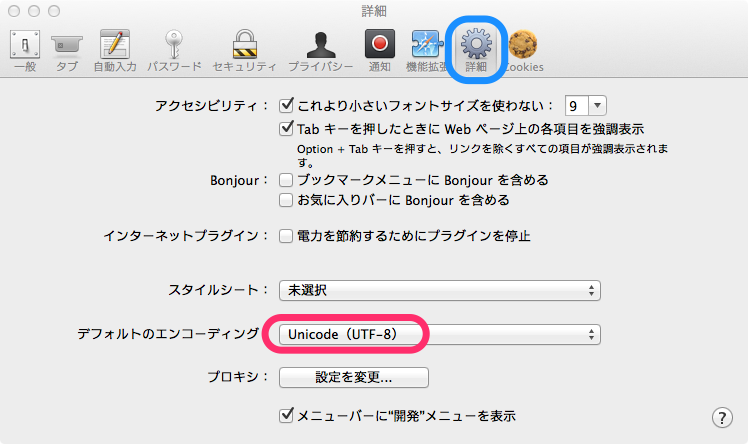
- Ver.20 以降:[設定]にある「文字エンコーディング」から選択(その様子を表示する)。 あるいは、 設定ウィンドウ - コンテンツパネル参照。
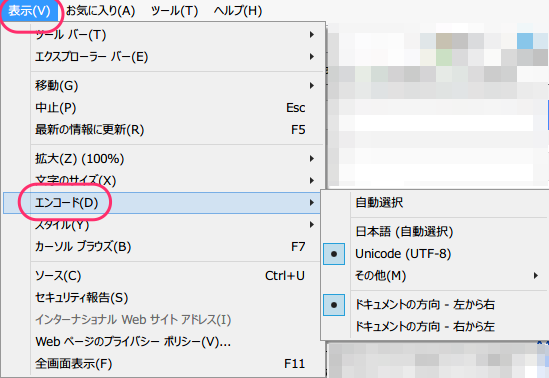
- メニューの[表示]/[エンコード]から選択(その様子を表示する)。
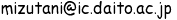
{kind=link}
{kind=link}
{kind=link}
{kind=link}