RパッケージRMeCabで用意されている関数
参考文献
- 石田 基広、「Rによるテキストマイニング入門」森北出版(2010)
Rのパッケージ RMeCabは、指定したファイルを形態素解析エンジン MeCabに渡して形態素解析を実施し、MeCabから返す次の結果様式
表層形 品詞 品詞細分類1 品詞細分類2 品詞細分類3 活用形 活用型 原形 読み 発音
を使ったさまざまな機能(関数)が用意されている。 その一つが、形態素の頻度で利用した関数 RMeCabFreq( ) で、テキスト内の形態素原形の登場頻度をデータフレームとして返すものであった。 RMeCabFreq 以外の関数を紹介しておこう。
パッケージRMeCabの利用法を知る
Rパッケージ RMeCab を利用するには(インストールした)パッケージ名を library() 関数の引数にセットして読み込む。 読み込んだパッケージの利用法を知るには、パッケージを読み込んだ以降で 「??パッケージ名」を入力する(パッケージ名を指定する場合には2つの「??」)。
> library(RMeCab) > ??RMeCab
すると、別ウィンドウにパッケージ RMeCabの関数一覧が表示され(実は、パッケージには他にも多数の有用な関数が用意されている)、6種の関数 RMeCabC、RMeCabDF、RMeCabDoc、RMeCabFreq、RMeCabMx、RMeCabText が表示される。 該当関数をクリックすると、その説明が表示される。 既に関数名が分かっている場合には、その使い方を知るにはパッケージを読み込んだ以降で 「?関数名」を入力する(関数名を指定する場合には1つの「?」)。
> library(RMeCab) > ?RMeCabFreq
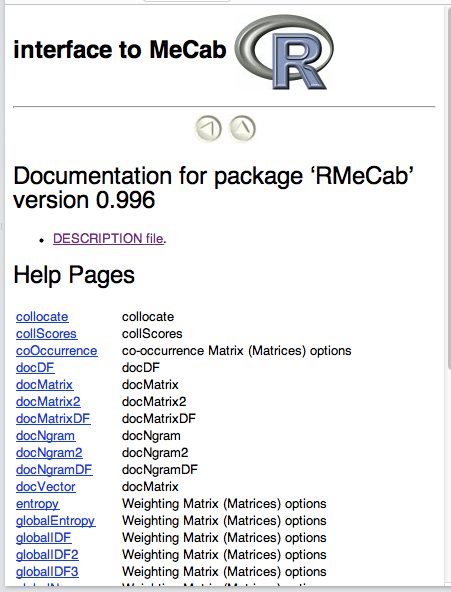
関数のヘルプの最後の行にある[Package RMeCab version 0.996 Index]で、indexをクリックすると、右図のように Interface to MeCabと題したウィンドウにRMeCabパッケージで提供される全関数とそのhelpへのリンクが得られる。 パッケージ RMeCab で用意されているMeCab間での関数は次のような33個の関数がある。
| collocate collScores coOccurrence docDF docMatrix docMatrix2 docMatrixDF docNgram docNgram2 docNgramDF docVector | entropy globalEntropy globalIDF globalIDF2 globalIDF3 globalNorm localBin localLogTF localTF makeNgram mynorm | Ngram NgramDF NgramDF2 print.docMatrix removeInfo RMeCabC RMeCabDF RMeCabDoc RMeCabFreq RMeCabMx RMeCabText |
RMeCabの主な関数群
RMeCabC, RMeCabText
RMeCabCは、引数に二重引用符「"」で挟んだ日本語文字列を与えてMeCabに渡し、その結果をリスト形式でそのまま返す関数。 リストの各要素にアクセスするには、[[要素番号]] と2重大括弧で指定する。
次の例は、「すもももももももものうち」の結果である。 リストの1番目を sumomo[[1]] で表示している。 sumomo2 はリスト形式から関数 unlist を使ってベクトル形式に直している。 ベクトル形式にするとその要素にラベル名でアクセスできる。 関数 names でベクトル sumomo2 のラベルを表示させた。 これを使うと、たとえば、ベクトル内のラベルが"名詞"だけを表示することができる。
> sumomo <- RMeCabC("すもももももももものうち")
> sumomo[[1]]
名詞
"すもも"
> sumomo2 <- unlist(sumomo)
> sumomo2
名詞 助詞 名詞 助詞 名詞 助詞 名詞
"すもも" "も" "もも" "も" "もも" "の" "うち"
> names(sumomo2)
[1] "名詞" "助詞" "名詞" "助詞" "名詞" "助詞" "名詞"
> sumomo2[names(sumomo2) == "名詞"]
名詞 名詞 名詞 名詞
"すもも" "もも" "もも" "うち"
RMeCabTextは、引数に日本語テキストファイル(文字符号化はRの設定値に一致していなければならない)を二重引用符「"」で挟んで指定して、MeCabに渡し、その結果をリスト形式でそのまま返す関数。 各リストの要素は、10要素からなるベクトルである。
次は、テキスト nakahara.txt を読み込んで、その1番目のリスト内容(10要素からなるベクトル)を表示している。
> nakahara <- RMeCabText("nakahara.txt")
file = nakahara.txt
> nakahara[[1]]
[1] "汚れ" "動詞" "自立" "*" "*" "一段" "連用形"
[8] "汚れる" "ヨゴレ" "ヨゴレ"
RMeCabFreq
関数 RMeCabFreq の詳しい使い方は、形態素の頻度分析にある。
docMatrix, docMatrix2, docMatrixDF
関数ファミリー docMatrix, docMatrix2, docMatrixDF は、検索語・文書行列(term-document matrix)を生成する関数である。 検索語・文書行列とは、あるterm(形態素原形)$t_j$ が文書ファイル $d_k$ 内に現れる頻度を $f_{ij}$ として、指定したカテゴリの全ての$m$語のterm $t_j (j=1\dots m)$ と検索する全ての$n$個の文書ファイル $d_k (k=1\dots n)$ について求めた行列 $F=(f_{jk})$ のことである。 検索語・文書行列によって、文書間の類似性(あるいは差異)を検討することができる。 ある文書集合においてあるterm群が高い頻度で登場している一方で、別の文書集合では同じターム群が低い頻度でしか現れないとすれば、それら2つの文書集合は語彙の使い方において別種の文書グループとして類別してもよいだろう。
docNgram, docNgram2, docNgramDF, Ngram, NgramDF, NgramDF2
関数ファミリー docNgram, docNgram2, docNgramDF, Ngram, NgramDF, NgramDF2 はテキストのNグラム(N-gram)統計を返す関数である。
collocate, collScores
関数ファミリー collocate, collScores は、コロケーション(collocation)の頻度とTスコアおよびMIスコアを調べる関数である。
RMeCabDF
関数 RMeCabDF は表データ(データフレーム)を読み込んで,表データの指定した列にある各行の形態素解析結果をリスト形式で返す。