|
�@���ʂȌ����I�v�V�������������Ă���T�[�`�G���W����p����Web�̓��v�������s���A���v�����c�[���Ƃ��ẴT�[�`�G���W���̗L�����ɂ��čl�@�������܂����i���������F03/31/2003�j�B
�͂��߂�
�@���{�b�g�ɂ���Ď��W���ꂽ�y�[�W�Q�������_���ȏW���ƂȂ��Ă��Ȃ����Ƃ͖��炩�ł��B
�@��ɂ́A�e�y�[�W�̔탊���N���ɑ傫�ȕ肪���邽�߁A�탊���N�̑����y�[�W�ɂ͓��B���₷���A�����łȂ��y�[�W�ɂ͓��B����Ȃ�A�C���f�N�V���O�����\�����傫���قȂ��Ă��܂��B
�@�܂��A�T�[�`�G���W���p�̃��{�b�g�̏ꍇ�A�������\�����コ���邽�߁A�Ǝ��̃A���S���Y����ݒ肵�Ă���A����ɕ����W���ƂȂ��Ă�����̂ƍl�����܂��B
�@�Ⴆ�A��Ɍ���悤�ɁA���`1)�ɂ��A�T�[�`�G���W���ɃL�[���[�h�𓊂��Ď��W���ꂽ�y�[�W�W���́A���̕��@�ɂ���Ď��W���ꂽ�y�[�W�������σT�C�Y���傫���Ƃ������ʂ������Ă��܂��B
�@�������Ȃ���A��ɁA�������琔�\���̃y�[�W��ێ����Ă���f�[�^�x�[�X�̓��e�́A�K������Web�S�̂̃X�i�b�v�E�V���b�g�ł͂Ȃ��Ƃ��Ă��A���ꂾ���ŋ����[����ł���ƌ�����ł��傤�B
�@�T�[�`�G���W���̒��ɂ́A�����L�[�Ŏw�肵����b���܂ރy�[�W���������邾���łȂ��A�h���C������N��y�[�W���ɂ��i�荞�@�\��������T�[�`�G���W�������݂��܂����A�Ƃ��Ɍ����L�[���w�肵�Ȃ��Ă��A��ʂɍi�荞�@�\�ƍl�����Ă�����̂����Ō������s����T�[�`�G���W��������܂��B
�@�Ⴆ�AGoogle�ł́A�u�����Ώۂɂ���T�C�g�E�h���C���v���ucom�v�Ƃ����w�肵�āuGoogle�����v�{�^�����N���b�N����ƁA�������ʂ͕\�����ꂸ�A
com ������������ɂ́Asite: �̑��Ɍ�������L�[���[�h����͂��Ă��������B
�Ƃ������G���[���\������܂��B
�@����ɑ��āAAlltheWeb�̏ꍇ�A�uDomain Fileters�v�́uInclude results from�v���Ɂucom�v�Ƃ����w�肷��Acom�h���C���̃y�[�W����Ԃ��Ă���܂��B
�@���݁A�����L�[���[�h���w�肵�Ȃ��Ƃ��A���������������̍s����T�[�`�G���W���́AAlltheWeb�iLycos�j�AAltaVista�ATeoma�̎O�ł��i��Lycos��FAST[AlltheWeb]�̃f�[�^�x�[�X���g�p�j�B
�@�����O�̃T�[�`�G���W���̂����AAltaVista�́A�������ʂ���K�͂ɂȂ�߂���ƁA�^�C���A�E�g�̂��߁A�\�����ʂ����肵�Ȃ��Ƃ�����_������܂��B
�@����͂��Ă���w�E����Ă������̂ł���2)�A�l�I�Ȉ�ۂƂ��ẮA��N�A�V�X�e������V���Ă���3)�A�Ƃ��ɁA���̌X���������ɂȂ����悤�Ɏv���܂��B
�@�������A�ʏ�̌����̂��߂ɂ͑S���x��͂Ȃ��̂ł����A���v�����̏ꍇ�͑傫�Ȗ��ƂȂ�܂��B
�@�Ⴆ�A�uurl:http�v�Ǝw�肵�Č��������ꍇ�A���ʂ�5���`16���͈̔͂ɕ��z���Ă��܂��܂��B
�@���������āAAltaVista�ɂ�钲�����ʂɂ͊܂߂܂���ł����B
�@�܂��ATeoma�́A�C���f�b�N�X�E�T�C�Y����5���y�[�W�Ƃ�⏬�������Ƃ�A�T�|�[�g���Ă��錾�ꂪ��r�I���Ȃ����ƁA����ɁA�������ʂ��傫���Ȃ�ƁA�\�������̂���10,000���ȉ����ۂ߂��邽�߁A��A���m���Ɍ����邱�ƂȂǂ��������܂��B
�@����AAlltheWeb�ɂ��ẮA�K�́A�����@�\�A����Ƃ��ɐ\�����Ȃ��ƌ�����ł��傤�B
�@�����ŁA�����ł́AAlltheWeb�𒆐S�ɂ��āA�T�[�`�G���W������݂�Web�̏�c�����Ă��������Ǝv���܂��B
��������
�@��ʂɁAWeb�̓��v�����ɂ����ėp������w�W�Ƃ��ẮA�ȉ��̂悤�Ȃ��̂��������܂��B
- �h���C���̕��z�i�Ƃ��ɁA.com���͂��߂Ƃ���C���^�[�i�V���i���E�h���C���̔䗦�j
- ���σt�@�C���E�T�C�Y�i���������܂��j
- �����N��
- �摜�^�O��
�@����A�T�[�`�G���W����p�������v�����ɂ����钲�����ڂ́A�T�|�[�g���Ă��錟���@�\�Ɉˑ����邱�Ƃ͌����܂ł�����܂���B
�@�����ł́A�ȉ���7���ڂɂ��Ē������s���܂����B
- �f�[�^�x�[�X�̋K�́iAlltheWeb, Teoma�j
- �h���C���̕��z�iAlltheWeb, Teoma�j
- ����̕��z�iAlltheWeb, Teoma�j
- �t�@�C���̐V�N�x�iAlltheWeb, Teoma�j
- �t�@�C���E�T�C�Y�iAlltheWeb�j
- �}���`���f�B�A�E�R���e���c�̔䗦�iAlltheWeb�j
- �t�@�C���E�^�C�v�̔䗦�iAlltheWeb�j
�f�[�^�x�[�X�̋K��
�@�����ł́AURL����http���܂ޑS�Ẵy�[�W���������邱�Ƃɂ���āA�T�[�`�G���W���̋K�͂𑪒肵�Ă��܂��B
�@���������āAFTP�T�[�o�ւ̃����N�͊܂܂�Ă��܂���B
�@�������ʂ͈ȉ��̒ʂ�ł��B
- AlltheWeb: 2,124,765,527 pages
- Teoma: 500,710,000 pages
�@AlltheWeb��Teoma��4.2�{�ƂȂ��Ă��܂��B
�@Table 1�i���j�ɂ́A����̒����Ƃقړ����ɍs��ꂽ���E�v���������f�X�N�ɂ����錟��������4)�̌��ʂ������Ă��܂��B
�@�����������́A15�̒����L�[��p���āA�e�T�[�`�G���W���̃q�b�g�������ꂼ�ꍇ�Z�������̂ł���A���T�s���Ă��܂��B
�@���Ȃ݂ɁA�����L�[�́Abiology, hardware, holiday, java, literature, market, movie, museum, outdoor, photography, activex, intranet, realaudio, shockwave, vrml�ƂȂ��Ă��܂��B
�@����ɂ��AAlltheWeb�i��FAST�j�͍ł��傫���T�[�`�G���W���̈�ł���A��͂�Teoma��4.2�{�ł��邱�Ƃ�������܂��B
Table 1. ���������� by �����f�X�N
| Open | FAST | Lycos | Yahoo | Wise | HotBot | Alta | Teoma | Google |
| 2003/03/28 |
| 378,675 | 354,355 | 354,485 | 223,130 | 198,133 | 118,055 | 116,374 | 99,113 | 64,162 |
| 100% | 93.58% | 93.61% | 58.92% | 52.32% | 31.18% | 30.73% | 26.17% | 16.94% |
| 2003/04/04 |
| 378,675 | 337,784 | 337,777 | 219,870 | 198,133 | 122,657 | 100,222 | 99,393 | 64,074 |
| 100% | 89.20% | 89.20% | 58.06% | 52.32% | 32.39% | 26.47% | 26.25% | 16.92% |
���������̒P�ʂ�1,000��
��Source: �����f�X�N(http://www.searchdesk.com/)
�@�܂��A���k���āAGreg R. Notes��Search Engine Showdown�ɂ�����2002�N12��31���̒���5)�ł́AAlltheWeb�̋K�͖͂�21���y�[�W��2�ʁATeoma��10����7�ʂƂȂ��Ă��܂��B
�@�����ł́A25�̒����L�[��p���Č������s���A�T�[�`�G���W���̑��ΓI�ȋK�͂𑪒肵����ŁA�f�[�^�x�[�X�̋K�͂������ł���T�[�`�G���W���iAlltheWeb�j����Ƃ��āA���ꂼ��̐�ΓI�K�͂��Z�o����ƂƂ��ɁA�T�[�`�G���W���E�T�C�g���炪���\���Ă���K�͂Ƃ̔�r���s���Ă��܂��B
�@Table 2�i���j�ɂ́ASearch Engine Showdown�ɂ�鐄��l�iestimate�j�A�ő�̃T�[�`�G���W���i�����ł�Google�j�Ƃ̔䗦�i%�j�A�T�[�`�G���W�������\���Ă���l�iclaim�j�A����l�ƌ��\�l�Ƃ̍��idiffer�j�������܂����B
Table 2. �T�[�`�G���W���̋K�͂̐��� by Search Engine Showdown
| _ | Google | All | Alta | Wise | Hotbot | MSN | Teoma | NL | Giga |
| estimate | 3,033 | 2,106 | 1,689 | 1,453 | 1147 | 1,018 | 1,015 | 733 | 275 |
| % | 100% | 69.4% | 55.7% | 47.9% | 37.8% | 33.6% | 33.5% | 24.2% | 9.1% |
| claim | 3,083 | 2,112 | 1,000 | 1,500 | 3,000 | 3,000 | 500 | 125 | 150 |
| differ | -50 | -6 | 689 | -47 | -1,853 | -1,982 | 515 | 608 | 125 |
���P�ʂ�100���y�[�W
��Source: Search Engine Showdown (http://www.searchengineshowdown.com/)
�@��ʂɁA�T�[�`�G���W���ɂ��ẮA���\�l�̕��������ꍇ�������̂ł����ATeoma�͌��\�l����5���y�[�W�ł���̂ɑ��āA����l����10���y�[�W�ƂȂ��Ă��܂��B
�h���C���̕��z
�@�g�b�v�E���x���E�h���C���iTLD�j�̕��z�́AWeb�̓��v�����ɂ����Ă����̗p�����w�W�̈�ł��B
�@�uWeb�ɂ�����h���C�����̕��z�ɂ����v�̒��ł��G�ꂽ�悤�ɁA�T�[�o�P�ʂ̃h���C���̕��z�ɂ��ẮAInternet Software Consortium�iISC�j�����N�Ɉ�x�������s���Ă��܂��B
�@Table 3�i���j�́A�T�C�g�P�ʂɂ�����com�h���C���̔䗦�̌o�N�I���ڂ����������̂ł�6)�B
�@ISC�ɂ�钲���ɂ����Ă������ł����A����ɂ��Acom�h���C���̔䗦������ɍ����Ȃ��Ă��邱�Ƃ�������܂��B
Table 3. com�h���C���̔䗦�̌o�N�I�ω�
| Month | % of .com |
| 6/93 | 1.5% |
| 12/93 | 4.6% |
| 6/94 | 13.5% |
| 12/94 | 18.3% |
| 6/95 | 31.3% |
| 1/96 | 50% |
| 6/96 | 68% |
| 1/97 | 62.6% |
��Source: Web Growth Summary(http://www.mit.edu/people/mkgray/net/web-growth-summary.html)
�@����A�y�[�W�P�ʂ̃h���C���̕��z�ɂ��ẮA�P�Ȃ铝�v�I����7), 8), 9)�����ł͂Ȃ��A�����_���ȃy�[�W�W�����쐬���邽�߂̕��@�_�Ƃ̊֘A�ł����Β������s���Ă��܂�10), 11)�B
�@��͂�A�����̒����ł́Acom�h���C���̔䗦�͒Ⴍ�Ȃ��Ă��܂����A��ɍs��ꂽ�����ł́A��50�����x�ƂȂ��Ă��܂��B
�@Table 4�i���j�ł́AAlltheWeb��Teoma��p�����y�[�W�P�ʂ̒������ʂƁAISC�ɂ��T�[�o�P�ʂ̒������ʁi2002�N12���j12)�Ƃ��r���Ă��܂��B
Table 4. Web�ɂ�����h���C���̕��z
| TLD | AlltheWeb | Teoma | ISC | Max | (all)-(isc) |
| .com | 48.30% | 49.71% | 23.63% | 49.71% | 24.67% |
| .net | 6.54% | 5.15% | 36.09% | 36.09% | -29.55% |
| .org | 6.33% | 9.06% | 0.65% | 9.06% | 5.68% |
| .edu | 2.20% | 7.90% | 4.35% | 7.90% | -2.14% |
| .de | 6.82% | 3.99% | 1.68% | 6.82% | 5.14% |
| .jp | 2.61% | 0.22% | 5.40% | 5.40% | -2.79% |
| .uk | 2.96% | 4.13% | 1.51% | 4.13% | 1.45% |
| .ru | 2.31% | 0.18% | 0.28% | 2.31% | 2.04% |
| .it | 1.29% | 1.67% | 2.25% | 2.25% | -0.96% |
| .au | 0.88% | 1.79% | 1.49% | 1.79% | -0.61% |
| .ca | 1.00% | 1.74% | 1.74% | 1.74% | -0.75% |
| .br | 1.62% | 1.12% | 1.30% | 1.62% | 0.32% |
| .us | 0.68% | 1.62% | 1.01% | 1.62% | -0.33% |
| .gov | 0.47% | 1.41% | 0.35% | 1.41% | 0.12% |
| .nl | 1.34% | 1.02% | 1.41% | 1.41% | -0.07% |
| .kr | 1.39% | 0.07% | 0.24% | 1.39% | 1.15% |
| .fr | 1.31% | 0.96% | 1.26% | 1.31% | 0.05% |
| .tw | 0.37% | 0.07% | 1.26% | 1.26% | -0.89% |
| .mil | 0.07% | 0.33% | 1.10% | 1.10% | -1.03% |
| .pl | 0.99% | 0.15% | 0.49% | 0.99% | 0.50% |
���O�҂̍ő�l�iMax.�j�̏��20�ʂ܂�
��Source: Internet Software Consortium (http://www.isc.org/)
�@�y�[�W�P�ʂƃT�[�o�P�ʂƂ̔�r�ł́Acom�h���C����net�h���C���̏��ʂ�����ւ���Ă���A���҂̔䗦�ɑ傫�Ȋi���̂��邱�Ƃ�������܂��B
�@�A���A���������̌��ʂ��T�ς��Ă��Acom�h���C���̃y�[�W�̔䗦�́A�������50����ƂȂ��Ă��邱�Ƃ���iHenzinger10): 47.03��, Bar-Yossef11): 49.15���j�A����̒������ʂ��Ó��Ȓl�������ꂽ���̂Ƃ�����ł��傤�B
�@�A���A�T�C�g�P�ʂł�net�h���C���̐����ɂ߂č����Ȃ��Ă��邱�Ƃ���A����Anet�h���C���̃y�[�W���啝�ɑ������邩���m��܂���B
�@�܂��ATeoma�͉p�ꌗ�̃h���C���̔䗦�������A�Ⴆ�Ajp�h���C���Ȃǂ́A���̒������ʂƊr�ׂđ傫��������Ă��邱�Ƃ���A���������W���s���Ă�����̂Ɛ��@����܂��B
����̕��z
�@AlltheWeb��49����ATeoma��10������T�|�[�g���Ă���A���ꂼ��A����̌�����w�肵���������s����悤�ɂȂ��Ă��܂��B
�@Table 5�i���j�ɁA���ꂼ��̒������ʂ������܂����B
Table 5. Web�ɂ����錾��̕��z
| Language | AlltheWeb | Teoma |
| English | 1,232,219,134 | 57.99% | 418,200,000 | 83.52% |
| German | 177,576,827 | 8.36% | 21,690,000 | 4.33% |
| French | 98,210,409 | 4.62% | 15,810,000 | 3.16% |
| Japanese | 84,694,266 | 3.99% | - | - |
| Korean | 69,764,481 | 3.28% | - | - |
| Spanish | 54,262,731 | 2.55% | 13,770,000 | 2.75% |
| Russian | 52,722,566 | 2.48% | - | - |
| Chinese(simp) | 51,142,024 | 2.41% | - | - |
| Portuguese | 43,429,176 | 2.04% | 7,309,000 | 1.46% |
| Italian | 37,446,108 | 1.76% | 10,830,000 | 2.16% |
| Dutch | 33,472,055 | 1.58% | 5,107,000 | 1.02% |
| Polish | 20,116,482 | 0.95% | - | - |
| Czech | 14,010,349 | 0.66% | - | - |
| Chinese(trad) | 12,610,430 | 0.59% | - | - |
| Swedish | 12,573,388 | 0.59% | 3,636,000 | 0.73% |
| Danish | 12,323,625 | 0.58% | 2,031,000 | 0.41% |
| Norwegian | 8,554,028 | 0.40% | 2,072,000 | 0.41% |
| Hebrew | 5,273,231 | 0.25% | - | - |
| Finnish | 5,224,201 | 0.25% | - | - |
| Hungarian | 4,689,208 | 0.22% | - | - |
��AlltheWeb�ɂ����20�ʂ܂�
�@�܂��A�p��y�[�W�̔䗦�ɒ��ڂ���ƁAAlltheWeb��60����ł���̂ɑ��āATeoma��80�����Ă��܂��B
�@�uWeb�ɂ����錾��̕��z�ɂ����v�ł́A�l�̃T�[�`�G���W����p���Č���̕��z�ׂĂ��܂����A�����̂����O�ɂ����āA��͂�p��y�[�W��60����ƂȂ��Ă��܂����B
�@����ɁATeoma�́A�T�|�[�g���Ă���10����̃y�[�W�����ŁA�S�̂�99.95�����߂Ă���A���̑��̌���͂قƂ�ǎ��W����Ă��܂���B
�@���������āATeoma���p�ꌗ�ɕ������W���s���Ă��邱�Ƃ͋^���Ȃ��悤�ł��B
�@���ɁAcom�h���C�����̉p��y�[�W�̔䗦�ׂĂ݂�ƁAAlltheWeb�ł�75.60���ATeoma�ł�92.36���ł����B
�@AlltheWeb�ɂ��Acom�h���C������25�����x�͉p��ȊO�̌���̃y�[�W�Ƃ������ƂɂȂ�܂��B
�@�Ⴆ�Ajp�h���C���̃y�[�W�i2.61���j�ɑ��āA���{��y�[�W�̔䗦�i3.99���j�͍����Ȃ��Ă��܂����A����炪�A.com���͂��߂Ƃ���C���^�[�i�V���i���E�h���C���Ɋ܂܂�Ă�����̂ƍl�����܂��B
�t�@�C���̐V�N�x
�@�T�[�`�G���W����p���āA�t�@�C���̐V�N�x�����邱�Ƃɂ͓�̈Ӌ`������܂��B
�@��́A�e�T�[�`�G���W���̃f�[�^�x�[�X�̐V�N�x�i�X�V�p�x�j�ł���A������́AWeb�S�̂̃t�@�C���Q�̐V�N�x�𖾂炩�ɂ��邱�Ƃł��B
�@AlltheWeb��Teoma�������y�ъ��Ԃ��w�肵�ăy�[�W���������邱�Ƃ��\�ł����A��{�I�ɁA�t�@�C���̃^�C���X�^���v�ɂ��ẮA�T�[�o�ɂ������ł��̂ŁA�^�C���X�^���v��Ԃ��Ȃ��T�[�o��A������^�C���X�^���v��Ԃ��T�[�o�Ȃǂ����݂��A���m�ȃf�[�^�������Ȃ��\���͔ۂ߂܂���B
�@�펯�I�ɂ́AWWW���\�z���ꂽ1989�N�ȑO�̃t�@�C���͑��݂��Ȃ��͂��ł����A���ۂɂ́A�����������t�@�C�����͂��Ȃ��瑶�݂��Ă��܂����AAlltheWeb�ɂ��ẮA���������i2003�N3��31���j�ȍ~�ɍ쐬���ꂽ�t�@�C������������Ă��܂��܂����B
�@�܂��AGraph 1�i���j�ł́A2003�N1��1������2003�N3��31���܂łɍX�V���ꂽ�t�@�C�������A������Ƃɂ��̐����J�E���g���Ă��܂��B
�@���Ȃ݂ɁAAlltheWeb�͒��������O�܂ł̃t�@�C�������݂��܂����ATeoma��2��8���ȍ~�̃t�@�C���͑��݂��܂���B
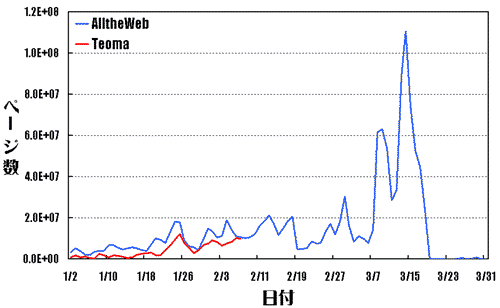
Graph 1. �T�[�`�G���W�����Ƃ̃y�[�W�̐V�N�x�iper Day)
�@���ɁAGraph 2�i���j�ɂ́A1990�N1������2003�N3���܂ŁA�e����1���ȍ~�ɍX�V���ꂽ�y�[�W���𑪒肵�A�f�[�^�x�[�X�S�̂Ƃ̔䗦�����߂�ƂƂ��ɁA���̌o�N�ω����v���b�g���Ă��܂��B
�@Teoma��2��7���ȑO�ɍX�V���ꂽ�t�@�C���������݂��܂���B
�@2003�N1��1���ȍ~�ɍX�V���ꂽ�t�@�C���̔䗦�́AAlltheWeb��61.70���ATeoma��32.59���ł��B
�@�܂��AAlltheWeb�́A2001�N9��1���ȍ~�ɍX�V���ꂽ�y�[�W�ŁA�f�[�^�x�[�X�S�̂�90�����Ă���ATeoma�͈�N�k����2000�N10��1���ȍ~�ƂȂ��Ă��܂��B�@
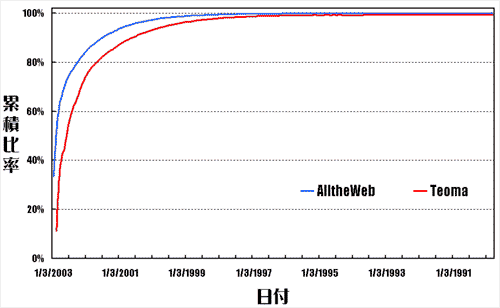
Graph 2. �T�[�`�G���W�����Ƃ̃y�[�W�̐V�N�x�Ɨݐϔ䗦�Ƃ̊W
�t�@�C���E�T�C�Y
�@Web�y�[�W�̃t�@�C���E�T�C�Y���܂��AWeb�̓��v�����ɂ����Ă����̗p�����w�W�ł��B
�@AlltheWeb�ł́Aadvanced search�̒��ŁA�t�@�C���E�T�C�Y���w�肵���������s���܂��B
�@�����ł́A1kb�܂ł�100byte���݁A1KB����20,000KB�܂ł�1KB���݂Œ������s���܂����i�ő�l��24.5MB�j�B
�@Graph 1�i���j�́A�o�C�g���Ɨݐσy�[�W���Ƃ̊W�����������̂ł��i100KB���镔���͊������Ă��܂��j�B
�@����ɂ��A10KB�܂łŗݐσy�[�W����10���y�[�W�ɒB���Ă���A49KB��20���y�[�W��˔j���Ă��܂��B
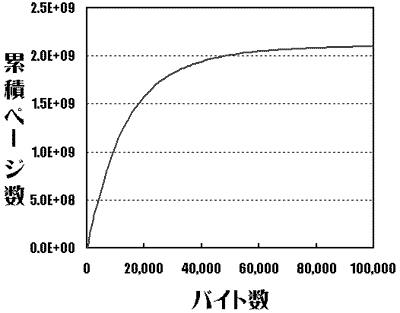
Graph 1. �y�[�W�E�T�C�Y�Ɨݐσy�[�W���Ƃ̊W
�@����ɁATable 6�i���j�ł́A����̒����ɂ��t�@�C���E�T�C�Y�̕��ϒl�ƁA�����̒������ʂƂ̔�r���s���Ă��܂��B
Table 6. Web�y�[�W�̕��σT�C�Y�̔�r
| _ | average file size |
| AlltheWeb, 2003 | 18,297 bytes |
| Mauldin, 19957) | 6,340 bytes* |
| Woodruff et al., 19968) | 4,400 bytes* |
| Bray, 19969) | 6,518 bytes |
| Bar-Yossef et al., 200011) | 11,655 bytes |
| Bar-Yossef et al., 200013) | 8,390 bytes |
| Cyveillance, 200014) | 10,060 bytes |
| Lawrence & Giles, 199915) | 18,700 bytes |
| Lawrence & Giles, 199915) | 7,300 bytes* |
| ���`�i�T�[�o�P�ʁj, 20011) | 7,385 bytes |
| ���`�i�L�[���[�h�����j, 20011) | 29,096 bytes** |
| ���`�i�f�B���N�g���j, 20011) | 6,831 bytes** |
| Average | 12,992 bytes |
| S.D. | 7,172 bytes |
*��HTML�^�O���������e�L�X�g�����̂݁i���ϒl�ɂ͊܂܂��j
**�͓��{��y�[�W�̂�
�@�����̒����ɂ�����Web�y�[�W�W���̎��W���@�ƃT���v�����́A���ꂼ��قȂ��Ă��܂��i�ڍׂɂ��Ă�Reference�̌��������Q�Ƃ��ĉ������j�B
�@�T�ˁA�ŋ߂̒����̕����T�C�Y�͑傫���X����������悤�ł��B
�@AlltheWeb�ɂ�镽�σT�C�Y��18,297bytes�ł���A�S�̂̕��ϒl��荂���ALawrence & Giles15)�ɂ��T�[�o�P�ʂŎ��W���ꂽ�y�[�W�Q�̃t�@�C���E�T�C�Y�̕��ϒl�Ǝ��ʂ��Ă��܂��B
�@�A���A�قړ������@�_�ɂ���Ď��W���ꂽLawrence & Giles�ƈ��`�i�T�[�o�P���j�Ƃ̌��ʂ͑傫���قȂ��Ă���_���w�E����܂��B
�@���̓_�Ɋւ��ẮA��͂�A�������@�_��p���čs��ꂽBar-Yossef��ɂ����̒�������7), 9)�ɂ����ق��F�߂��邱�Ƃ���A��KB�̍��ق͌덷�͈͓̔��ł���ƌ�����̂����m��܂���B
�@�����̂����A�ˏo���Ă���̂́A���`�i�L�[���[�h�����j�ł����A����̓T�[�`�G���W����p�����L�[���[�h�����ɂ���č쐬���ꂽ�W���ł��邱�ƁA����ɁA���{��݂̂̏W���ł��邱�Ƃ���A���Ȃ�����W���ƂȂ��Ă�����̂Ɛ��@����܂��B
�@�܂��A���`�i�f�B���N�g���j�́AYahoo! JAPAN����3�z�b�v�܂łŎ��W���ꂽ��500���y�[�W�̏W������A����ׂɑI�����ꂽ5,000�y�[�W�̕��ϒl�ł���A��͂�A���{��y�[�W�݂̂ƂȂ��Ă��܂��B
�}���`���f�B�A�E�R���e���c
�@Web�y�[�W�����݂̂悤�Ȏ�v�ȃ��f�B�A�ւƖ��i�����������͂̈�́A�}���`���f�B�A�E�R���e���c�������ł���u���E�U�iMosaic�j�̊J���ł������Ƃ����̂�����ł��B
�@���݂ł́AWeb�̕\���͂͋ɂ߂č����A�����郁�f�B�A��Web�o�R�ŗ��p���邱�Ƃ��ł���悤�ɂȂ��Ă��܂��B
�@AlltheWeb�ł́A����̃}���`���f�B�A�E�R���e���c�A���邢�́A�X�N���v�g���w�肵�āA�������܂ރy�[�W���������邱�Ƃ��ł��܂��B
�@���̋@�\�𗘗p���āA�y�[�W���̃}���`���f�B�A�E�R���e���c�̏����܂����B
�@AlltheWeb�Ŏw��ł���͈̂ȉ��̔��̃R���e���c�ł��B
- Images
- Audio (midi, wav, au)
- Video (mov, qt, avi)
- RealVideo & RealAudio
- Macromedia Flash
- Java applets
- JavaScript
- VBScript
�@Table 7�i���j�́A�e�R���e���c���܂ރy�[�W�iInclude�j�ƁA����̃R���e���c�݂̂��܂ރy�[�W�iInclude(only)�j�̐��Ƃ��̔䗦�����������̂ł��B
Table 7. Web�ɂ�����}���`���f�B�A�E�R���e���c�̔䗦
| - | Include | Include(only) |
| Images | 1,814,533,513 | 85.40% | 779,979,405 | 42.99%* |
| Audio | 9,325,397 | 0.44% | 302,695 | 3.25%* |
| Video | 5,321,464 | 0.25% | 104,533 | 1.96%* |
| Real | 7,977,098 | 0.38% | 119,517 | 1.50%* |
| Flash | 101,245,609 | 4.77% | 10,700,205 | 10.57%* |
| Java applets | 37,314,444 | 1.76% | 1,094,544 | 2.93%* |
| JavaScript | 1,064,472,816 | 50.10% | 70,265,161 | 6.60%* |
| VBScript | 6,720,566 | 0.32% | 245,667 | 3.66%* |
| Total | 3,046,910,907 | 143.40% | 223,056,868** | 10.50% |
| Database Size | 2,124,765,527 | 100% | 2,124,765,527 | 100% |
*��Include�ɑ���Include(only)�̔䗦
**�̓}���`���f�B�A�E�R���e���c��X�N���v�g��S���܂܂Ȃ��y�[�W
�@�\�z�ʂ�ł������͉̂摜�t�@�C���ł���A�S�̂�85���ɒB���Ă��܂��B
�@���ɑ����̂�JavaScript�ŁA50�����Ă���AHTML��⋭����X�N���v�g����Ƃ��āA���Ȃ��ʓI�Ȃ��̂ƂȂ��Ă��邱�Ƃ��M���܂��B
�@�܂��AFlash��4.77���ő�O�ʂƂȂ��Ă��܂����Aswf�t�@�C�����쐬����ɂ�Macromedia��Flash���K�v�ł��邱�Ƃ��l������A���̕��y���͒��ڂɒl���܂��B
�@�܂��A����̃R���e���c�����܂܂Ȃ��y�[�W�iInclude(only)�j������ƁA�摜�t�@�C���������AFlash��10.57���ƍł������Ȃ��Ă���A�I�[���C���E������swf�t�@�C���̓������悭�\���Ă���ƌ����܂��B
�@���āATable 8�i���j�́A����̃}���`���f�B�A�E�R���e���c���A����y�[�W���ő��̂ǂ̃R���e���c�ƕ��p����Ă��邩���������̂ł��B
�@�\�͍s�����ɓǂ݁A�Ⴆ�A�摜�t�@�C���iIM�j���܂ރy�[�W�̂����A�I�[�f�B�I�E�t�@�C���iAU�j�����܂ނ��̂�0.49�����݂��邱�Ƃ������Ă��܂��B
�@�t�ɁA�I�[�f�B�I�E�t�@�C�����܂ރy�[�W�̂����A�摜�t�@�C�����܂ނ��̂�95.04���Ƃ������ƂɂȂ�܂��B
Table 8. �}���`���f�B�A�E�R���e���c�Ԃ̊W
| IM | AU | VI | RE | FL | JA | JS | VS |
| IM | _ | 0.49% | 0.28% | 0.43% | 4.80% | 1.98% | 54.56% | 0.33% |
| AU | 95.04% | _ | 5.22% | 10.08% | 5.99% | 3.61% | 53.51% | 0.48% |
| VI | 97.14% | 9.15% | _ | 11.15% | 7.34% | 2.62% | 54.48% | 0.35% |
| RE | 97.47% | 11.79% | 7.44% | _ | 5.43% | 3.17% | 59.01% | 0.39% |
| FL | 85.94% | 0.55% | 0.39% | 0.43% | _ | 2.44% | 68.45% | 1.03% |
| JA | 96.05% | 0.90% | 0.37% | 0.68% | 6.63% | _ | 56.83% | 0.53% |
| JS | 93.00% | 0.47% | 0.27% | 0.44% | 6.51% | 1.99% | _ | 0.52% |
| VS | 89.51% | 0.67% | 0.28% | 0.47% | 15.55% | 2.94% | 81.76% | _ |
�@�������ʂ͗�����ɓǂނƈ��̌X����ǂ݂Ƃ邱�Ƃ��ł��܂��B
�@�Ⴆ�A�I�[�f�B�I�E�t�@�C���A�r�f�I�E�t�@�C���AReal�t�@�C���͂��ꂼ��A���̃R���e���c�Ɣ�r���āA���݂ɕ��p����邱�Ƃ������悤�ł��B
�@�܂��AFlash�͉摜�t�@�C���ƕ��p�����䗦�����̃R���e���c�Ɣ�r���ĒႭ�Ȃ��Ă��邱�Ƃ�������܂��B
�t�@�C���E�^�C�v
�@�ߔN�AHTML�t�@�C���ȊO�̃t�@�C���������ł���T�[�`�G���W��������������܂��B
�@Web��ł́A���̍����w�p���pdf�`����ps�`���Œ���邱�Ƃ������A�l�I�ɂ͑�Ϗd�Ă��܂��B
�@����Ɋւ��āASearch Engine Showdown�ł́AGoogle�AAlltheWeb�AAltaVista�AHotBot�̎l�̃T�[�`�G���W���ɂ�����HTML�t�@�C����PDF�t�@�C���̔䗦�����Ă��܂��iTable 9(��)�j�B
Table 9. �T�[�`�G���W���ɐ�߂�HTML��PDF�̔䗦 by Search Engine Showdown
| - | Web | PDFs | Other Files |
| Google | 8,565 | 88.0% | 1,008 | 10.4% | 159 | 1.6% |
| AlltheWeb | 6,133 | 90.8% | 591 | 8.7% | 33 | 0.5% |
| AltaVista | 4,977 | 91.8% | 442 | 8.2% | - | - |
| HotBot | 3,529 | 95.9% | 151 | 4.1% | - | - |
��Source: Search Engine Showdown (http://www.searchengineshowdown.com/)
�@���ɁAAlltheWeb��p�����������ʂ�Table 10�i���j�����܂��B
�@AlltheWeb�ł́APDF�AFlash�AWord�̎O�̃t�@�C���`�����w�肵�Č������邱�Ƃ��ł��܂��B
�@����ɂ��AHTML�t�@�C���ȊO�̃t�@�C���`���̔䗦�͂��Ȃ�Ⴂ���̂ƂȂ��Ă��܂��B
Table 10. Web�ɂ�����t�@�C���E�^�C�v���Ƃ̔䗦
| file format | number of files | percentage |
| Adobe pdf | 15,786,144 | 0.74% |
| Macromedia Flash | 1,306,044 | 0.06% |
| MS Word | 2,920,871 | 0.14% |
| the others | 2,104,752,468 | 99.06% |
| Database Size | 2,124,765,527 | 100% |
Web���v�̕W�����ɂ���
�@�����������T�ς���ƁA�y�[�W�̎��W���@�A�T���v�����A���������A�������ڂ͋�X�ł��B
�@�����������l�X�Ȓ����Ԃɂ�����~���Ȕ�r���s����悤�AWeb���v�̕W�����ɂ��ĐG��Ă��������Ǝv���܂��B
�@�W���I�ȓ��v���ڂƂ��ẮA�@Web�̓�����[�I�Ɏ����Ă�����́A���܂��A�A�����R�X�g�̒Ⴂ���̂��I�肳���ׂ��ł��傤�B
�@�Ƃ��ɁA��҂̊ϓ_�́A�����Ό����Ƃ��ꂪ���ł����A�ƂĂ��d�v�ł��B
�@���������ɂ����čł���������Ă��鍀�ڂ́A�t�@�C���E�T�C�Y�ƃh���C���̕��z�ł����A������Web�̓������悭�\���Ă���Ƃ��������ނ���A���̒����R�X�g���Ⴂ����ɑ��Ȃ�܂���B
�@����A�t���I�ȑ�������Ȃ���Ȃ�Ȃ��ꍇ�A��⒲���͏��Ȃ��Ȃ�܂��B
�@�Ⴆ�A�y�[�W���̕������A�����N���A�摜������Web�y�[�W�̏�Ԃ��L�q����̂ɁA�ɂ߂ē����I�Ȏw�W�ł���ƍl�����܂����A�t�@�C���E�T�C�Y��h���C���Ɣ�r���āA�����R�X�g�͍����ƌ����܂��B
�@�܂��A������������ꍇ�A�����R�[�h�̖�肩��A���S�ɐ��m�Ƀ^�O���������ł��Ă��邩�ǂ����Ƃ������x�̖�������ł��傤�B
�@����A����̕��z�ɂ��ẮA����Ƃ��������������ڂł����A�ʏ�̓��v�I�����ł͂قƂ�njڂ݂��邱�Ƃ�����܂���B
�@����́A������������ɂ́A���̕���ɐ��ʂ��Ă��Ȃ���Ȃ炸�A��ʓI�ȃR���s���[�^�E�T�C�G���X�̌����҂��S�Ă�������������ɐ��ʂ��Ă����ł͂Ȃ�����ł��B
�@���������Ӗ��ŁA�T�[�`�G���W����p���������́A�����R�X�g�̖ʂ����łȂ��A�ȒP�ɁA����̕��z���ł���Ƃ����Ӗ��ł��D��Ă���ƌ�����ł��傤�B
������
�@�����ł́AAlltheWeb��Teoma��p���āAWeb�̓��v�������s���܂����B
�@���������̌��ʂƂ̔�r�ɂ����Ă������Ȃ悤�ɁAAlltheWeb�̂悤�ȁA�ɂ߂ċK�͂��傫���A�����̌���ɑΉ����Ă���T�[�`�G���W����p����A�[���ɁAWeb�̓��v�����̂��߂̃c�[���Ƃ��Ď��p��������ƌ�����ł��傤�B
�@�A���A�c�O�Ȃ���AAltaVista�AHotBot�ANorthernLight�̂悤�ɁA���Ă͓��v�����ɗ��p�ł����T�[�`�G���W�����A���炩�̗��R�ŁA���p�ł��Ȃ��Ȃ��Ă���A���̐��͌����X���ɂ���܂��B
�@�܂��AGoogle�̂悤�ɁA�T�[�o�ւ̉ߕ��ׂ�r�����邽�߂ɁA�I�[�g�E�N�G�������W�F�N�g����T�[�`�G���W��������A��������\��������܂��i�A���AGoogle�̏ꍇ�AGoogle API�𗘗p����A���1,000���̃I�[�g�E�N�G���𑗐M���邱�Ƃ��\�ł��j�B
�@�T�[�`�G���W���̏��Ɖ�����w�i�W���A���͂�{�����e�B�A�ł���Ă��鎞��ł͂���܂���̂ŁA����A�ǂ��Ȃ��Ă������͕�����܂���B
Reference
- ���`�P. "Web�����ɂ�����T���v���W���̎��W�@," ������w���ۊW�I�v. Vol.11, No.2, p.269-293(2001)
- Notes, Greg R. "AltaVista Inconsistencies," Search Engine Showdown: The User's Guide to Web Searching.
- Morrissey, Brian. "AltaVista Makes a Comeback," internetnews.com. November 12, 2002.(���{��ł��R�`��)
- ���E�v. "�����̓f�[�^ 2003�N," �����f�X�N.
- Notes, Greg R. "Search Engine Statistics: Database Total Size Estimates," Search Engine Showdown: The User's Guide to Web Searching.
- Gray, Matthew. "Web Growth Summary," Internet Statistics: Growth and Usage of the Web and the Internet.
- Mauldin, Michael L. "Measuring the Web with Lycos
," proceedings of the the 3rd International World Wide Web Conference, Darmstadt, Germany(1995)
- Woodruff, Allison., Aoki, Paul M., Brewer, Eric., Gauthier, Paul., Rowe, Lawrence A., "An Investigation of Documents from the World Wide Web," proceedings of the the 5th International World Wide Web Conference, Paris, France(1996)
- Bray, Tim. "Measuring the Web," proceedings of the the 5th International World Wide Web Conference, Paris, France(1996)
- Henzinger, Monika R., Heydon, Allan., Mitzenmacher, Michael, Najork, Marc. "On Near-Uniform URL Sampling," Proceedings of the 9th International World Wide Web Conference.
- Bar-Yossef, Ziv., Berg, Alexander., Chien Steve., Fakcharoenphol, Jittat., Weitz, Dror. "Approximating Aggregate Queries about Web Pages via Random Walks," 26th International Conference on Very Large Databases(VLDB 2000).
- Internet Software Consortium. "Distribution of Top-Level Domain Names by Host Count: Jan 2003,"
- Bar-Yossef, Ziv., Berg, Alexander., Chien Steve., Fakcharoenphol, Jittat., Weitz, Dror. "Uniform Sampling from the Web via Random Walks,"
- Johanson, Aimee. "Internet Exceeds 2 Billion Pages: Cyveillance Study Projects Internet Will Double in Size by Early 2001," Cyveillance: Newsroom: 2000 Press Releases. 10 July 2000.
- Lawrence, Steve., Giles, Lee. "Accessibility and Distribution of Information on the Web," Nature. Vol.400, pp107-109(1999)
|