|
Henzinger, Monika R.1, Heydon, Allan.2, Mitzenmacher, Michael.3, Najork, Marc.2 "On Near-Uniform URL Sampling". Proceedings of the 9th International World Wide Web Conference. (2000)
1. Google, Ins., 2. Compaq System Research Center, 3. Harvard University
※図表、注・引用文献は原文献をご参照下さい。
1. はじめに
URLの無作為抽出が可能であれば、Webの構成に関する様々な論点に関して、標準的な統計的手法を適用することが可能となるが、現在のところ、そういった手法は発見されていない。
本研究では、通常のサンプリング・アプローチを改良し、より均一なURLの標本抽出が可能となるような手法を提案するとともに、その手法の妥当性を検証するための実験を行った。
1.1. 先行研究
URLの無作為抽出は、主に、Webページ数の推計との関わりにおいて検討されてきた2), 14), 15)。
本稿では、Webを有向グラフ(directed graph)としてモデル化し、PageRankのような確率分布を基盤としたランダムウォークを拡張して、より均一なURL集合の生成を行えるようにする。
1.2. ランダムウォークとPageRank
ランダムウォークは、通常、マルコフ性を持っている。
その意味するところは、現在の状態から次の状態への推移は、それ以前の状態に依存しないという点にある。
また、Brin & Page4)によって考案されたPageRankは以下の式によって定義される。
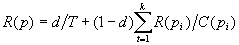
ここで、R(p)はページpのPageRank、TはWebの全ページ数、確率変数dは通常0.1<d<0.15、piはpに対してリンクを張っているページ、C(pi)はpiの持つリンク数である。
2. サンプリング・アプローチ
2.1. 決定論的アプローチ
最も自然なアプローチは、Web全体、または、充分に大きな部分集合を収集するものであるが、Webが巨大であるために効果的ではない。
また、実際に「充分に大きな」値を定義することが不可能である。
2.2. Mercatorによるランダムウォーク
次に考えられるのは、ランダムウォークであり、リンクの中から無作為にリンクをたどり、リンクのないページに行き着いたら、履歴の中から再びランダムにリンクをたどっていくという手法である。
ここでは、Mercatorと呼ばれるロボットを用いた(100 threads, 10,000 initial starting points)。
3. 数学的基礎
ランダムウォークによるサンプリングの問題点は、多くのページからリンクを張られているページを、より頻繁に訪れるという点にある。
われわれは、これを是正し、より均一なサンプルを収集するために、PageRankの逆数を用いた確率分布を生成することとした。
但し、そこでは、ランダムウォークの間に得られる情報から如何にしてPageRankを算出するかという問題が提起される。
そこで、われわれは二つの手法を考案した。
一つは「visit ratio(VR)」であり、特定のページXについて、ランダムウォークの最中にXが出現した頻度を、ウォークの長さによって除したものである。
これはウォークが充分に長い場合PageRankの近似値となることが期待される。
もう一つは、ランダムウォークによって、全てのノード(ページ)と全てのエッジ(リンク)が訪問されたと仮定して、そのPageRankを算出する方法である(=PR)。
4. 限界
以上の方法論によって対象とされるのは、真の意味でのWeb全体ではなく、アクセス可能であり、スタティックな、他のページと繋がっている(well-connected)Webに過ぎない。
また、開始点バイアスや、ページの訪問が独立ではない等といった問題点も存在する。
5. ランダム・テスト・ベッド
われわれのサンプリング・アプローチの妥当性を検証するために、10,000,000のノードと82,086,395のエッジを持つグラフを(仮想的に)生成した。
ここでは、総リンク数と総被リンク数が一致しており、ページごとのリンク数は1/K2.38、同じく被リンク数は1/K2.1という指数法則によって規定されている。
また、リンク数は5~12、被リンク数は5~18の間に分布している。
まず、ランダムウォークによって848,836個のノードを訪問し、そこから、三つの異なる手法(VR、PR、均一なランダムウォーク)を用いて、2,000ずつ標本抽出を行った。
そして、それぞれのサンプルのリンク数(out-degree)、被リンク数(in-degree)、PageRankの分布を比較した(→Figure1-3)。
その結果、均一なランダムウォークよりも、VRやPRによるサンプリングの方が、より母集団の特性に近い値を示していると言える。
6. Webのランダムウォーク・サンプリング
次に、実際のWeb上で三度のランダムウォークを行った(→Table1)。
同じ10,258個の開始点集合を利用したにも拘わらず、三つすべてで一致したのは155ページに過ぎず、訪問した全てのページのうち83.2%は他のウォークでは訪れられていないことが分かった(→Figure4)。
7. 応用
7.1. トップレベルドメインの分布の推定
8000万ページの決定論的アプローチによるトップレベルドメインの分布と、三つのサンプリング手法による、それぞれ、1万ページのTLDの分布とを比較した(→Table2)。
三つの結果は比較的似通っており、ここでは、高いPageRankを持つページを必ずしも抑制できていないようである。
7.2. サーチエンジンの収集範囲
ここでは、われわれのURLのサンプルが均一なものであると仮定して、サーチエンジンの収集範囲を推定する。
まず、VR、及び、PRを用いて、それぞれ、12,000ページを取得し、それぞれのページ中で最も出現頻度の少ない10の語彙を結合して、検索キーとし、8つのサーチエンジンに対して検索を行った。
出力結果のうち、URLが完全に一致したもの(exact match)、ホスト名が一致したもの(host match)、及び、少なくとも一件以上の出力があったもの(non-zero match)を測定した(→Figure5-7)。
VR、PRの結果はいずれも似通っている。
Search Engine Watchによる相対規模の結果との比較では、Googleの相対規模が大きい点が指摘される。
8. 結論
これからも頑張る。
|