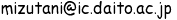新しい属性値を計算する--人口密度の色別表示
2010年に実施した平成22年国勢調査に基づいたデータを市町村別にまとめたGISデータを使って、1平方メートルあたりの人口密度[$\mbox{人}/m^2$]を計算してその様子を眺めてみよう。
データの準備
日本政府の地図で見る統計(統計GIS)から「データダウンロード」をクリックしてページ移動する。データダウンロードは次の手順に従う。
- Step1:統計調査(集計)の選択で、ここでは「平成22年国政調査(小地域)」を選ぶ。
- Step2:統計表を選択で、ここでは「男女別人口総数及び世帯総数」をチェックして[次へ]ボタン。
- Step3:地域選択で、ここでは(興味ある市町村を)東京都の 千代田区、中央区、港区、新宿区、文京区、台東区、墨田区、江東区、小平市、東村山市、国分寺市、国立市、西多摩郡瑞穂町、西多摩郡日の出町、西多摩郡檜原村、西多摩郡奥多摩町などのデータをダウンロードする。 それぞれのデータは市町村+測地コードがついたフィルだ内に4種類のファイルが格納されてダウンロードされる。 どのファイルが何処のどんなデータを区別してフォルダ名を適当に変更して(今後のために、分かりやすく整理して保存しておく)。
- Step4:データダウンロードでは「境界データ」のみとして、しかも各種あるデータ形式から該当する市町村の『世界測地系緯度経度・Shape形式』のデータをクリックしてダウンロードする(世界測地系でも沢山の形式があるので注意する)。 定義書も併せて入手しておく。
属性テーブルと新規属性
こうして得られたデータとして新宿区の場合をつかって以下を説明する。 新宿区のshapeデータ h22ka13104.shp をレイヤパネルに Drag&Dropする。 図パネルには新宿区の輪郭が区内の町別境界データで区切られで表示されているはずだ。
演習:MOJI属性
上の手順で得られたGISデータの「定義書」を開いてその内容を把握しておこう。 定義書によると、新宿区内の町名はMOJIフィールドに「町丁・字等名称」として保持されている。 これを町名を表示してみよ。-
 レイヤパネルの新宿区データを選択して右クリックして「属性テーブルを開く」を選択する。
右図のように、属性テーブルの上端には横並びで「定義書」で定義されたフィールド名が並んでいる。
新宿区の場合のレコード数は、0番目の「西落合4丁目」から、151番目の「霞ヶ丘町」まである。
属性テーブルの最下段にアイコンが並んでいる。
レイヤパネルの新宿区データを選択して右クリックして「属性テーブルを開く」を選択する。
右図のように、属性テーブルの上端には横並びで「定義書」で定義されたフィールド名が並んでいる。
新宿区の場合のレコード数は、0番目の「西落合4丁目」から、151番目の「霞ヶ丘町」まである。
属性テーブルの最下段にアイコンが並んでいる。
- 上図の属性テーブルにおいて、赤で囲った「編集モードの編集」ボタン
 を押すと、上の図のように町境界が赤のx印となって、属性テーブルが変種モードになったことがわかる。
を押すと、上の図のように町境界が赤のx印となって、属性テーブルが変種モードになったことがわかる。
-
さらに、上図の属性テーブルにおいて青で囲った「フィールド計算機のオープン」ボタン
 を押すと、次のフィールド計算機のウィンドウが現れる。
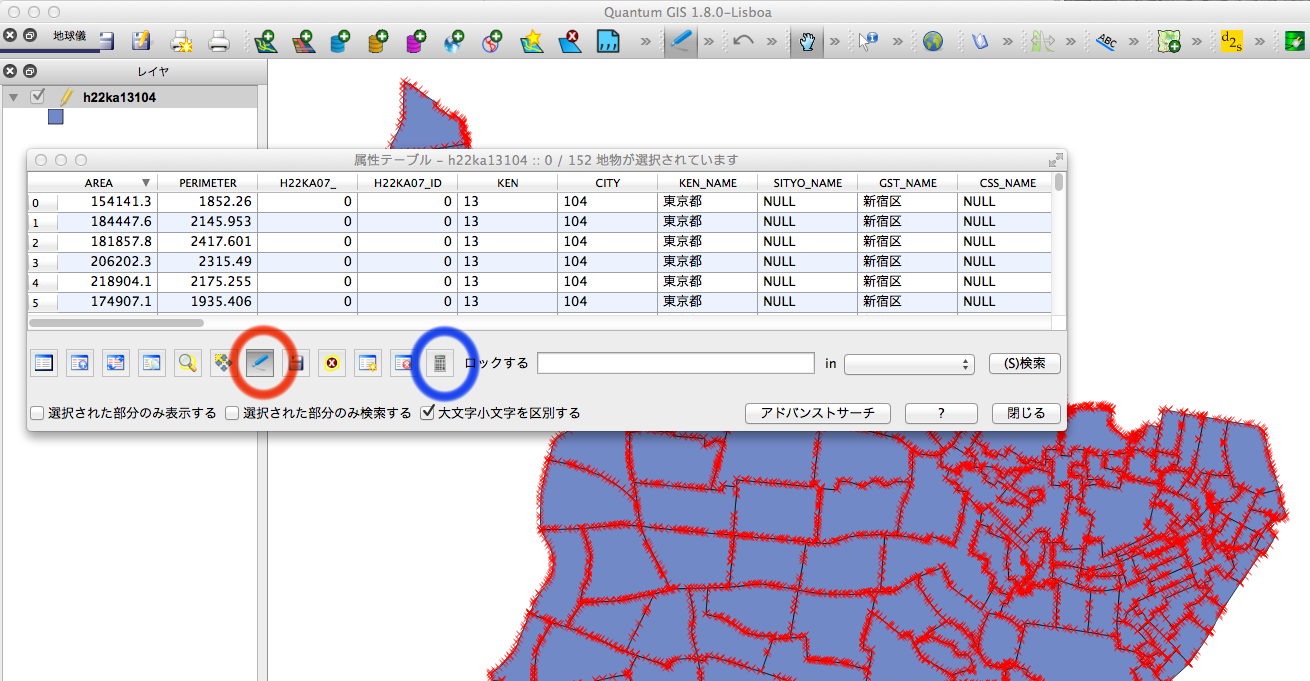
を押すと、次のフィールド計算機のウィンドウが現れる。現在の属性テーブル(定義書)にない人口密度を表すフィールド DENSITY を作成し、その人口密度を計算した結果を新たに属性テーブルに追加してみよう。
- フィールド計算機のウィンドウに、「新しいフィールドを作る」をチェック。
- 出力フィールド欄に DENSITY と入力。
- 計算結果の出力フィールドタイプとして、「小数点付き」を選ぶ。
- ウィンドウ下の式に、フィールド DENSITY の値の計算式を入力する。 定義書より、人口密度[$\mbox{人}/m^2$]は、各町ごとに 人口総数(JINKO) ÷ 面積(AREA) で計算できる。 ただし、QGISでは、右図のように計算式はフィールド名を2重引用符(")で囲む必要がある。 図のように、ウィンドウ中段のフィールドと値からフィールド名称をダブルクリックして選択すると自動的に2重引用符で挟まれるので、この機能を使うと誤入力を防ぐことができる。
- 必要事項の入力と計算式を確認してから[OK]ボタンを押す。
- 属性テーブルの最右端に DENSITY フィールドが定義され、各レコード事に密度が計算されていることを確かめる。
-
新宿区データを選択して右クリックから「削除」しようとすると、その「レイヤーの変更を保存しますか?」を聞いてくる。
[Save]ボタン押して結果を保存して(同じ名前でDENSITYフィールドが追加計算されて保存される)、新宿区データをレイヤから削除してみる。
再び、Drag & Dropして読み込ませて、属性テーブルの内容を確かめておく。
以降、データは保存されるとする。 -
 右図のように、新宿区データを選択して右クリックから「プロパティ」(のスタイル・タブ)を選択。
ただし、
右図のように、新宿区データを選択して右クリックから「プロパティ」(のスタイル・タブ)を選択。
ただし、
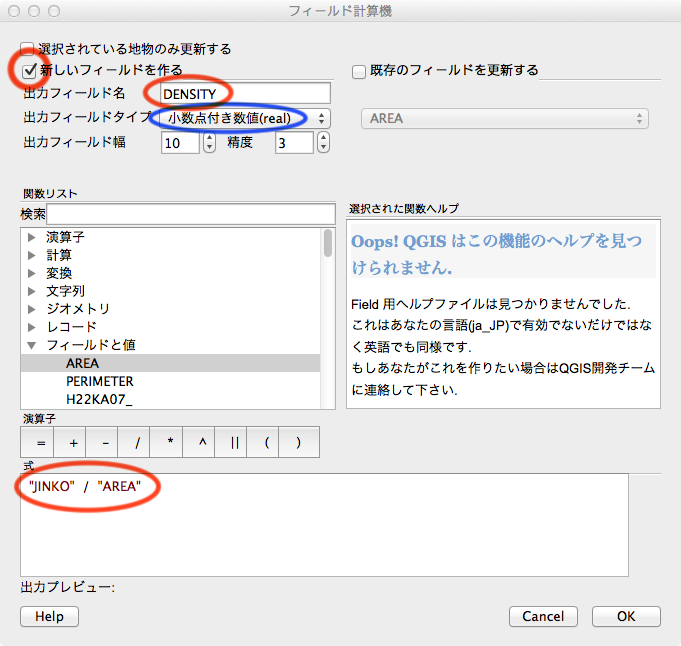
- ここではポリゴンの塗りつぶし方法そちて、(赤く囲んだように)「段階に分けられた」を選ぶ
- カラムとして(赤く囲んだように)計算した人口密度によって塗り分けるために「DENSITY」を選択して
- モードは、(青く囲んだように)8段階の等間隔としておこう(新宿区のような高い人口密度が期待できる地域で八段階としておけば十分だろう)。
こうして定義したスタイルを[Apply]する。 - この「8段階(段階を分ける数値にも意味がある)に分けられたスタイル」を保存しておく。 他の市町村で、同じように人口密度 DENSITY を定義して計算し、地域による人口密度の様子を同じ基準によって比較するために、ここで保存したスタイルを読み込んでポリゴンを塗り分けるのでである。 ここでは、スタイルファイルとして population-level-layer.qml として保存した(拡張子 . qml は自動的に付与される)。
-
 こうして、新宿区の町別人口密度が右図のように得られる。
こうして、新宿区の町別人口密度が右図のように得られる。
市町村の合併した人口密度を図示
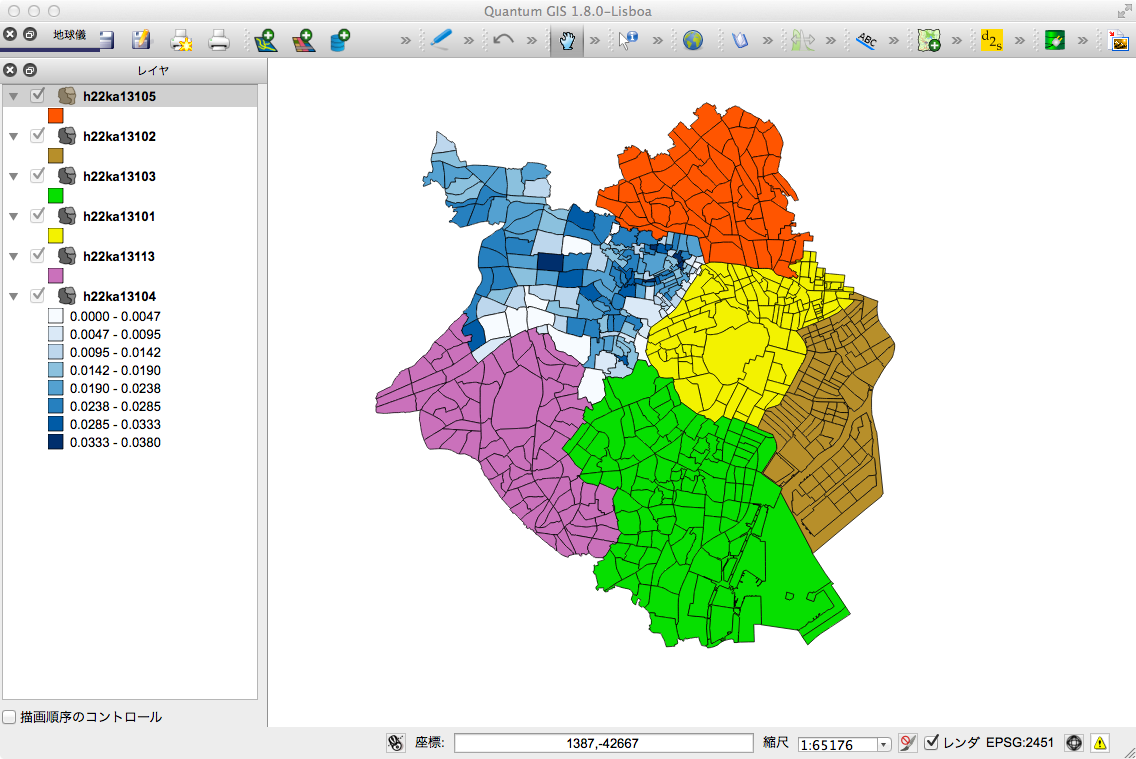 右図は、新宿区以外に、渋谷区、文京区、港区、千代田区、中央区のデータをレイヤーにDrag & Dropした結果である。
新宿区以外は町の人口密度による塗り分けはしていない。
右図は、新宿区以外に、渋谷区、文京区、港区、千代田区、中央区のデータをレイヤーにDrag & Dropした結果である。
新宿区以外は町の人口密度による塗り分けはしていない。
演習1:都心部の人口による町域の塗り分け
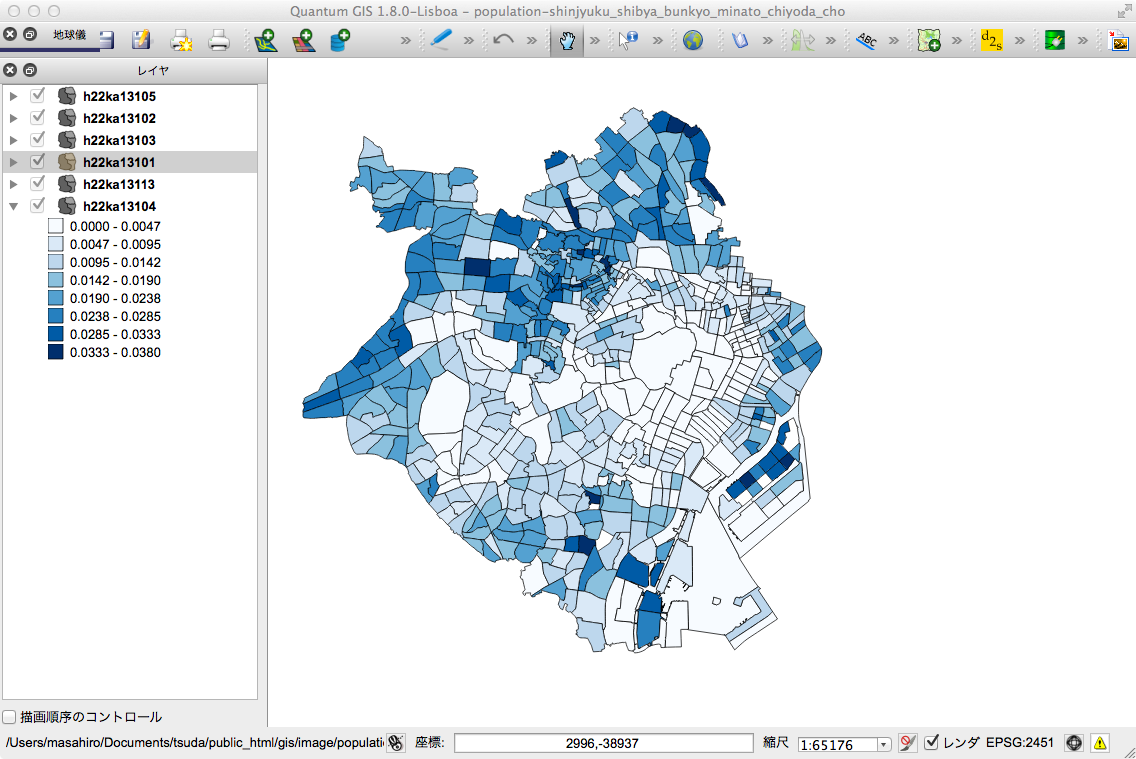 右図のように、新宿区、渋谷区、文京区、港区、千代田区、中央区の町域を上で定めた8段階等間隔によるスタイルで塗り分ける。
明治神宮、皇居、芝浦など区域は人口が少ないことが観察できる。
右図のように、新宿区、渋谷区、文京区、港区、千代田区、中央区の町域を上で定めた8段階等間隔によるスタイルで塗り分ける。
明治神宮、皇居、芝浦など区域は人口が少ないことが観察できる。
演習2:首都圏の人口町域の塗り分けに交通網と日本地図を重ねる
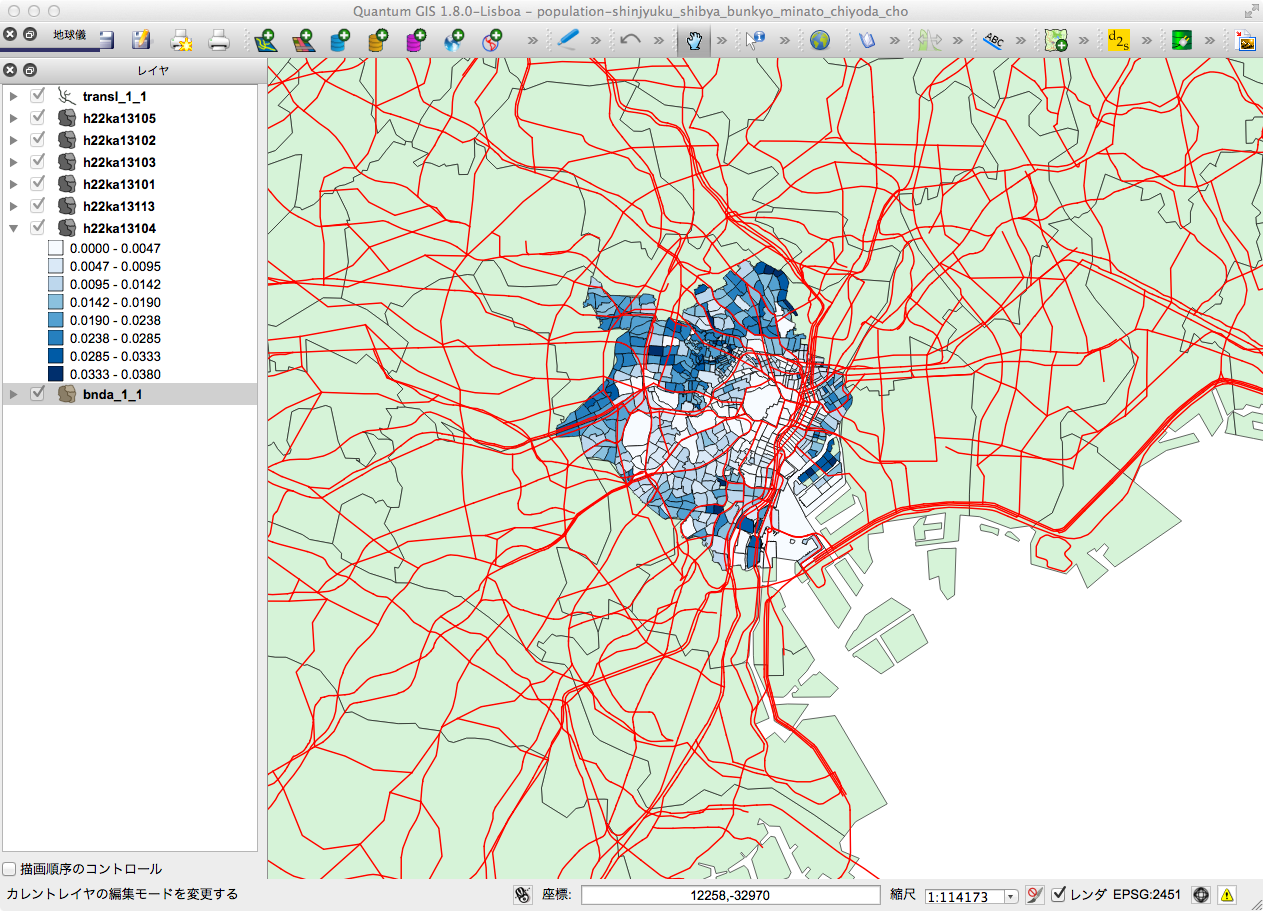 は、QGISを起動してみる(1)で利用したみんなの地球地図から取得したデータから、
行政域 bnda_1_1.shp と交通網 transl_1_1.shp をレイヤパネルにさらに読み込んで得た首都圏の様子である。
は、QGISを起動してみる(1)で利用したみんなの地球地図から取得したデータから、
行政域 bnda_1_1.shp と交通網 transl_1_1.shp をレイヤパネルにさらに読み込んで得た首都圏の様子である。
ただし、幾つかの注意が必要である。
いままでのレイヤの重ね合わせは、ポリゴンなどの情報は重複していなかった(行政域が異なるので、線でしか重ならない)。
今の場合、日本の行政域のポリゴンは日本全体を覆うポリゴンなので、上で作成した首都圏の区を覆ってしまうし、交通網も覆う。
この問題を解決するには,次の2つの方法を組み合わせる。
- 複数のレイヤ情報の描き順を変更する
QGISでは、レイヤパネルに上から並んだレイヤ情報は下から順番に描かれる。 上図の場合には、最初に一番下にあるレイヤ bnda_1_1(行政域)が最初に描かれ、その上に h22ka13104から順に h22ka13105 までの(ポリゴンとしては重ならない)各区の人口密度塗り分けが描かれ、最後に描かれるのがレイヤパネルの最上位に位置する transl_1_1(交通網)である。 - レイヤのプロパティの「スタイル・タブ」の透過率を変更する
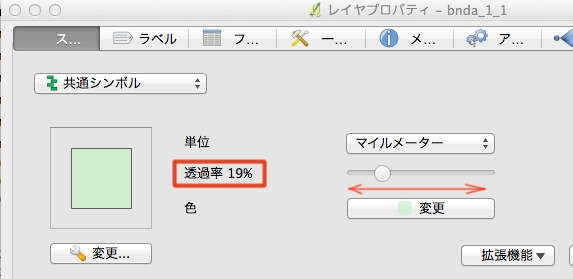 仮に、全体を覆ってしまうレイヤ bnda_1_1(行政域)が最後に描かれる(レイヤパネルの最上位に位置)とした場合であっても、そのプロパティのスタイル・タブの「共通シンボル」の透過率を高める(左右にスライドする)と上のレイヤが透明化され下のレイヤが透けて見える。
仮に、全体を覆ってしまうレイヤ bnda_1_1(行政域)が最後に描かれる(レイヤパネルの最上位に位置)とした場合であっても、そのプロパティのスタイル・タブの「共通シンボル」の透過率を高める(左右にスライドする)と上のレイヤが透明化され下のレイヤが透けて見える。